前后端分离的场景下,用户访问的是前端服务器,后端开发的接口是给前端用的,这个要谨记。
了解一下前后端不分离的模式
@student.get("/index.html")
async def getAllStudent():
students = await Student.all()
return students这里直接返回的话,返回的是json的数据,可以在接口文档中看的很清楚。
前后端不分离的话,我们需要将数据嵌入前端中,然后返回给用户。
# 需要导入jinja2
from fastapi.templating import Jinja2Templates
from fastapi import Request
@students.get('/students')
async def get_all_students(request: Request): # 这里必须携带Request的实例
all_students = await Student.all()
templates = Jinja2Templates(directory=r".\chapter3\学习ORM\apis\templates")
return templates.TemplateResponse(
"index.html",{ # 模板文件写这里
"request": request,
"students": all_students #传递的参数写这里
}
)模板文件需要在合适的位置编辑好,数据插入的位置,类似这样
<html>
<body>
<ul>
{% for student in students %}
<li>姓名:{{ student.name }}, 学号:{{ student.student_number }}</li>
{% endfor %}
</ul>
</body>
</html>再尝试访问,就可以看到返回的渲染后的页面了
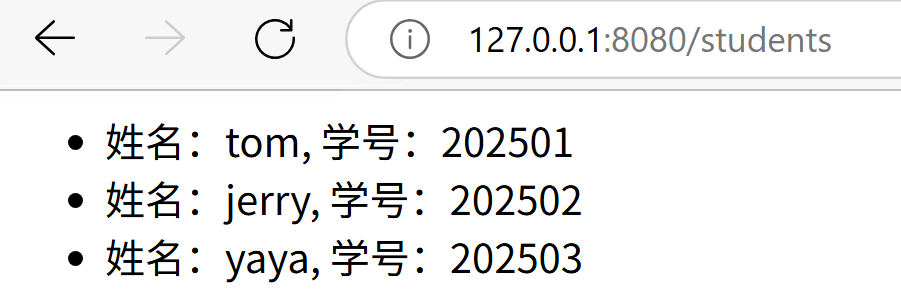
然后 老师讲了一下bootstrap的一些用法,看看就好。