基础使用不再赘述;
- 开发使用有界面浏览器,部署使用无头浏览器
- 基于css选择器的话,可以试试在浏览器直接复制元素的selector
- 还有name属性
selenium使用cookie:
添加:
driver.add_cookie({'xx':'xx'})
删除:
driver.delete_cookie('name')
driver.refresh()
获取:
get_cookies()

下面重点看一下元素定位不到的几种情况以及处置方式
1.元素未加载完成
网络延迟或者JavaScript渲染,可能会找不到
解决方式:添加对应的等待时间,让元素充分加载完成后再进行具体的操作,等待的三种方式:
- 强制等待;
固定时间,比较死板
举例:time.sleep(3)
- 显式等待
设定一个时间,程序自动在这段时间内反复寻找目标元素,超时报错
举例(比如最多等5秒):from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.wait import WebDriverWait el = WebDriverWait(driver, 5).until(EC.presence_of_element_located((By.XPATH,'xxxx xpath'))) el.click() - 隐式等待
原理和显式等待类似
举例:driver.implicitly_wait(3)
2.iframe或frame内的元素
iframe或frame内的元素,是无法直接定位的,那么必须要先切换,才能进行元素定位
例如:
driver.switch_to.frame(xxx)
driver.switch_to.frame(driver.find_element_by(By.XPATH,'frame的xpath'))
切换进去后,在进行find元素的操作
driver.switch_to.default_content() #返回根frame
driver.switch_to.parent_frame() #返回上一级frame
3.元素id或者属性是变化的
页面中同一元素的xpath(浏览器直接复制的)每次刷新都会变的时候,需要我们根据网页结构手写xpath。
例如:
以xxx开头或以xxx结尾或包含xxx的元素

不管成功与否,都提取text:

4.元素不可交互
- 元素是通过JavaScript动态生成的,那么元素不在html中,使用selenium无法直接定位,那么可以通过编写JavaScript脚本对元素的强制操作或者属性修改之后再进行定位操作。
- selenium支持嵌入JavaScript脚本的执行;
网上类似的解决方案有很多,比较简单的事在一个页面里面通过JS程序修改页面上的内容:
原博文:Python在selenium里面注入JavaScript程序的方法【20210815】
主要方法:driver.execute_script("JS脚本内容")
5.元素被遮挡
元素被广告、弹窗等遮挡,可以刻通过编写JavaScript脚本实现
也可以通过JavaScript对页面上的元素实现监听,对出来的元素及时进行相应的操作,JavaScript中可以使用MutationObserver接口来实现DOM数是否改变的监听。
6.特殊元素的处理
- 警告框
alert、confirm、prompt、input等等


页面跳转需要切换驱动,比如点击了某个超链接打开了新的页面
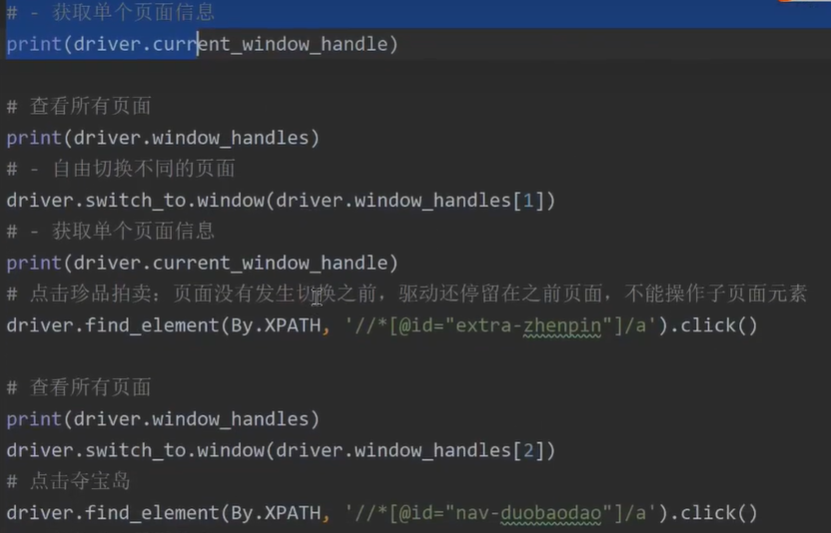
公司值班建单系统自动建单的实现的思路:
先用selenium实现个人账号的登录,并且拿到对应的cookie,将cookie字典化;
然后使用request模块携带刚刚拿到的cookie和payload向对应接口发送post请求,拿到需要建单的元素项。
再想办法将拿到的元素传给selenium,进行后续的建单操作
